karpenter-best-pratices
Karpenter no EKS: Melhores Práticas e Aprendizados Práticos
Compartilhando experiências práticas, desafios e estratégias bem-sucedidas para usar o Karpenter no gerenciamento de nós worker do EKS.
Adoção Inicial e Versionamento
- Desafio Inicial: Versões 0.x (ex: 0.37.5) apresentaram instabilidade no rollback (0.36.x, 0.35.x). Dificuldades com CRDs e rollbacks.
- ⚠️ Aprendizado Chave: Esperar por Versões Estáveis. A adoção da v1.x (ex: 1.3+) é mais confiável e madura.
- Recomendação: Inicie com uma versão v1.x estável (ex: 1.3 ou superior).
Estratégia de NodePools: Segregação é Fundamental
- ✅ Melhor Prática: Dividir workloads em NodePools distintos baseados em características.
- Exemplos de Segregação:
Infraestrutura / Controlplane(ArgoCD, monitoramento leve)Observabilidade / Controlplane-Observability(Máquinas maiores/específicas)Ingress / Controlplane-Traffic-Control(Istio, Nginx Ingress)Aplicação / Dataplane(Workloads gerais)
- Benefícios: Tipos de instância direcionados, atualizações independentes, melhor isolamento.
Seleção de Tipos de Instância: Flexibilidade Vence
- Abordagem Antiga: Definir manualmente famílias de instância (C5, M5…).
- Problema: Restringir escolhas causava problemas, especialmente com Spot.
- ✅ Melhor Prática: Deixar o Karpenter escolher!
- Defina requisitos (zone, arch) e não permitidos (burstable, gerações antigas).
- Conceda flexibilidade para encontrar instâncias ótimas (ex: c7i-flex, m7i-flex).
- Estratégia Spot: Oferecer Spot + On-Demand em não-produção. Karpenter prioriza Spot, com fallback para On-Demand.
- Spot Instace Adivisor: https://aws.amazon.com/pt/ec2/spot/instance-advisor/
Gerenciando Atualizações e Rotações (AMI & Nós)
- Requisito: Rotação de nós (ex: 30 dias) e atualização de AMI (ex: 60 dias) por segurança/compliance.
- Desafio: Atualizar tudo de uma vez causa interrupção.
- ✅ Melhores Práticas (Combinadas):
- Budgets do Karpenter: Controlar a taxa de substituição.
0durante horário comercial (sem trocas).1na janela de manutenção (troca sequencial, um por vez).
- Atualizações Escalonadas: Janelas de manutenção diferentes por NodePool.
- Budgets do Karpenter: Controlar a taxa de substituição.
budget do karpenter
"pro" = [
{
"nodes" = "1"
},
{
"nodes" = "0"
"schedule" = "0 8 * * *" # 05 da manhã Brasil
"duration" = "21h" # 05 da manhã até 02 da manhã
},
{
"nodes" = "0"
"schedule" = "0 3 * * 5,6,0" # Na sexta, sábado e domingo não haverá consolidação
"duration" = "24h"
},
...
]
O “Ingrediente Secreto”: Configuração da Carga de Trabalho
- ‼️ Crítico #1: Requests & Limits:
- Pods DEVEM ter
requests&limitsdefinidos
- Pods DEVEM ter
- ‼️ Crítico #2: Pod Disruption Budgets (PDBs):
- ESSENCIAIS para disponibilidade durante operações do Karpenter (drenagem/troca de nós).
- Informam quantos pods devem permanecer disponíveis.
- Cuidado: PDBs muito restritivos (
minAvailable: 100%) podem bloquear a troca de nós. Equilibre disponibilidade e flexibilidade.
- ‼️ Crítico #3: TopologySpread:
- Ele vai indicar a distriuição dos pods. Quantos pods irá ficar em cada maquina/zona
Automação e Implantação
- Deployment: Terraform + Helm Chart é viável.
- Tratamento de Término: EventBridge + SQS + Termination Handler para Spot e eventos agendados.
- Onde Rodar o Karpenter:
- Não em nós gerenciados por ele mesmo.
- Usar Managed Node Group dedicado OU
- ✅ Fargate (simplifica o ciclo de vida do Karpenter, rodar junto com CoreDNS).
Monitorando o Karpenter
- Mecanismo: Endpoint de métricas (
:8080/metrics). - Ferramentas:
- Prometheus & Grafana: Bom dashboard da comunidade disponível.
- Datadog: Boa integração e dashboards próprios.
- Recomendação: Monitore reconciliações, contagem de nós, utilização de recursos e erros.
Monitorando o Karpenter
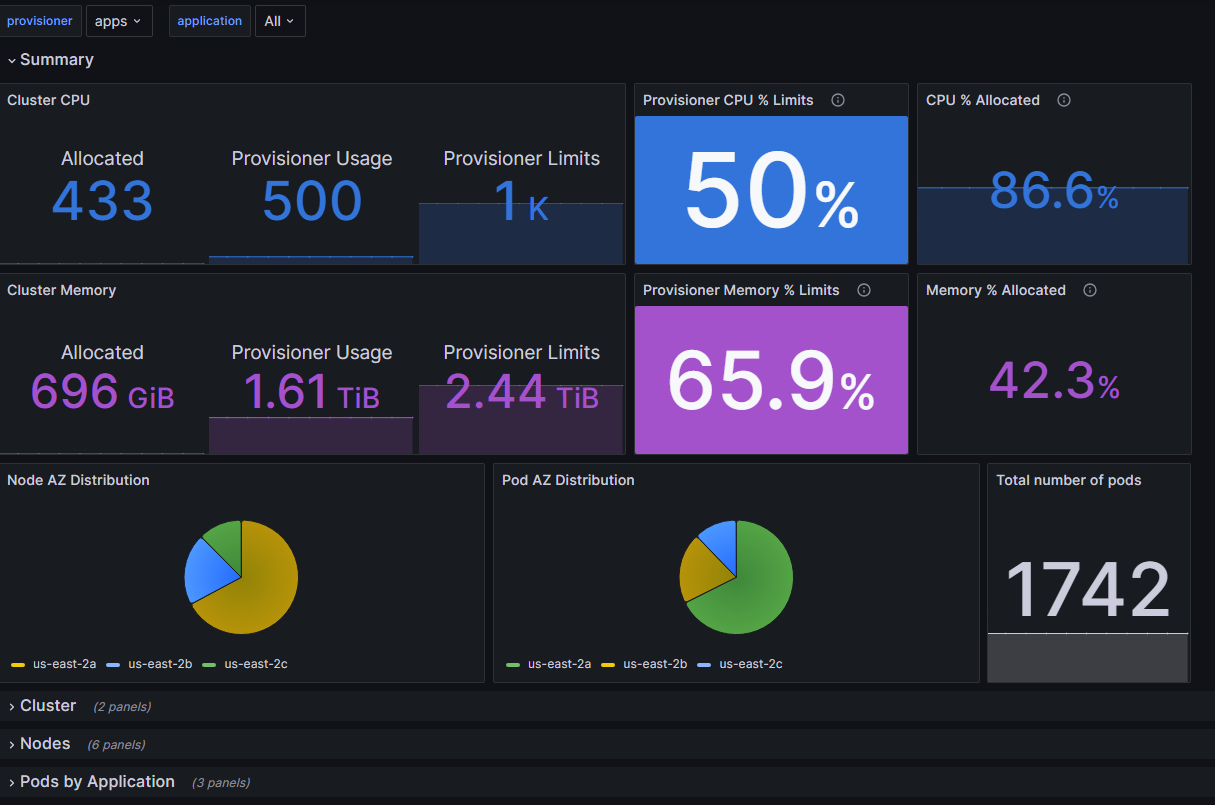
Monitorando o Karpenter
FinOps e Otimização de Custos
- Motivação: Economia é um benefício significativo (20% base, até 60%+ com Spot).
- Estratégias:
- Instâncias Spot: Usar intensamente em não-prod, avaliar com cuidado em produção.
- Rightsizing: Deixar Karpenter escolher tamanhos baseado em
requests. - Agendamento de Workload: Escalar réplicas para zero fora do horário. Karpenter remove nós vazios (controlado por Budgets).
- Consolidação: Karpenter tenta automaticamente consolidar pods (respeitando PDBs/Budgets).
FinOps DEV & HOM
- Motivação: Zerar as instancias em DEV e HOM
- Estratégias:
- Zerar os deployments: Modificar o workload para ficar zerar as replicas.
- Limists dos nodepools: Modificar os limits do nodepool para 0.
-
Remover os nodepools: Com a remoção do nodepools, as ec2 provisionadas são removidas.
Considerações Avançadas e Futuras
- Velocidade de Startup: Karpenter prefere nós rápidos. AMIs lentas (> ~1.5 min) causam problemas.
- BottleRocket: Inicialização mais rápida. Futuro: Usar BottleRocket Operator para gerenciar atualizações do SO.
- Graviton (ARM): Adoção futura planejada.
- AWS Auto Mode: Simplifica a configuração inicial (Karpenter 1.3+).
Conclusão e Principais Pontos
- ✅ Poderoso: Melhor que Cluster Autoscaler para muitos cenários.
- ⏱️ Estabilidade: Use versões v1.x.
- 🧱 Segregue NodePools: Adapte a infraestrutura.
- ⚙️ Configure Workloads: Requests/Limits, PDBs e TopologySpread são cruciais.
- 🗓️ Use Budgets/Agendamento: Controle interrupções e atualizações.
- 💡 Dê Flexibilidade: Deixe Karpenter escolher instâncias.
- 📊 Monitore Ativamente: Entenda o comportamento.
- 🤖 Abrace a Automação: Deployment, término, atualizações.